Kompresja z łacińskiego"compressio" znaczy "ściśnięcie", znaczy zmniejszenie objętości. W informatyce odnosi się do zmniejszania objętości i wielkości danych, umożliwiający do odtworzenia pierwotnych danych.
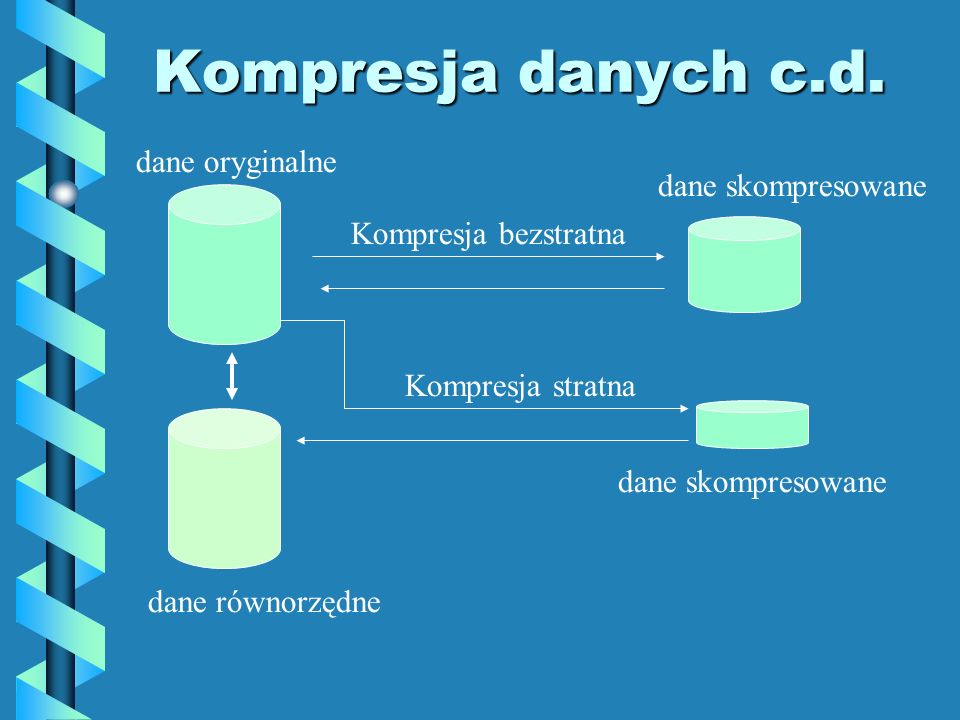
Dekompresją nazywamy proces odtworzenia pierwotnych danych. Na rysunku poniżej przedstawiono schemat wykonywania kompresji i dekompresji:

Zastosowania kompresji:
Bez kompresji nie istniałyby standardy typu JPEG, DVD, Blu-Ray lub MP3 itp.
Pozwala ona na efektywne używanie łączy telekomunikacyjnych, jest m.in stosowana w modemach
Rodzaje kompresji:
stratna (lossy compression) - w tej kompresji dane odtworzone są podobne do danych pierwotnych i na ogół różnią się od nich w sposó trudny do zauważenia.
dźwięki
muzyka - format MP3
obrazy- format JPG
filmy - format MPEG
Bazuje ona na niedoskonałości ludzkich zmysłów. Nie dostrzegają one niewielkich zmian barw, różnic w dżwięku lub w fakturze obrazu. Do widocznej utraty jakości może doprowadzić wieloktrotne powtarzanie cyklu kompresji i dekompresji.

bezstratna (lossless compression) - w tej kompresji dane odtworzone są identyczne z danymi pierwotnymi
teksty
programy komputerowe
bazy danych
pliki z innymi danymi jak arkusze kalkulacyjne itp.
niektóre rodzaje grafik - format GIF i TIFF itd.
Dekompresją nazywamy proces odtworzenia pierwotnych danych. Na rysunku poniżej przedstawiono schemat wykonywania kompresji i dekompresji:
Zastosowania kompresji:
Bez kompresji nie istniałyby standardy typu JPEG, DVD, Blu-Ray lub MP3 itp.
Pozwala ona na efektywne używanie łączy telekomunikacyjnych, jest m.in stosowana w modemach
Rodzaje kompresji:
stratna (lossy compression) - w tej kompresji dane odtworzone są podobne do danych pierwotnych i na ogół różnią się od nich w sposó trudny do zauważenia.
dźwięki
muzyka - format MP3
obrazy- format JPG
filmy - format MPEG
Bazuje ona na niedoskonałości ludzkich zmysłów. Nie dostrzegają one niewielkich zmian barw, różnic w dżwięku lub w fakturze obrazu. Do widocznej utraty jakości może doprowadzić wieloktrotne powtarzanie cyklu kompresji i dekompresji.
bezstratna (lossless compression) - w tej kompresji dane odtworzone są identyczne z danymi pierwotnymi
teksty
programy komputerowe
bazy danych
pliki z innymi danymi jak arkusze kalkulacyjne itp.
niektóre rodzaje grafik - format GIF i TIFF itd.


